

Журналистика данных в Центральной Азии – это сложно. Зачастую журналистам приходится писать сотни запросов и оцифровывать килограммы рукописных документов. Член совета директоров Глобальной сети журналистов-расследователей и старший советник по вопросам медиа Интерньюс Нетворк Олег Хоменок дает советы журналистам, которые только начинают работать с данными – какие ошибки не стоит совершать с самого начала?
Олег Хоменок приехал в Кыргызстан на первый центральноазиатский Datalab, который завершился в Бишкеке 25 января. Вместе с коллегой Виталием Власовым он учил журналистов и экологов региона правильной работе с большими данными и их визуализации. Для тех, кто не попал на встречу, он рассказал об основах работы с данными в интервью cайту «ЛИВЕНЬ. Living Asia».

Существует несколько уровней работы журналиста с публичными данными:
- Журналисты получают данные от органов государственной власти через ответы на информационные запросы.
Мы пишем соответствующее письмо, и нам приходит в ответ либо напечатанный на принтере документ, либо этот же письменный сканированный документ, который нам надо оцифровать.
Этот уровень очень базовый и почти не содержит данных, готовых к работе – нам все равно приходится их обрабатывать: вручную переводить в цифровой вид и вбивать в электронные таблицы.
- Данные появляются на сайтах органов государственной власти в виде поискового интерфейса, открытых реестров.
Это, например, реестр юридических лиц, который существует в Кыргызстане – мы можем зайти туда, набрать имя компании или ее налоговый номер и получить ответ о ее деятельности.
Этот ответ – единичный информационный юнит, который не подходит для работы журналиста с большим массивом данных. Ему нужно совершить многократные действия для того, чтобы получить из этого реестра информацию о большом количестве компаний – тогда мы с этим сможем работать.
Несколько лет назад этот процесс родил скрапинг – специально настроенные программы-роботы формируют запросы и выкачивают базу данных, которая размещена на каком-либо сайте.
Вслед за скрапингом следует парсинг – процесс последующей обработки выкачанной информации и преобразование ее в интерфейс, в котором журналист уже может работать.
- Партнер «ЛИВЕНЬ. Living Asia» – информационный портал Kloop – в прошлом году провел встречу с бывшим сотрудником Google Скотти Алленом, который рассказал о скрапинге и работе с данными. Запись трансляции этого мастер-класса вы можете посмотреть по ссылке.
- За счет денег налогоплательщиков государство само преобразует эти массивы данных уже в машиночитаемый вид, который готов для работы с ними.
Они доступны для скачивания в самых разных форматах обработки баз данных, и они рождают уже соответствующие интерфейсы, удобные для пользователя, когда мы сами настраиваем инструменты для поиска в этом массиве того, что нам нужно.
Три совета для журналистов, начинающих работать с данными
Не бойтесь ошибок и не думайте, что все получится сразу
В Кыргызстане очень малое количество данных, которые подходят для такой работы. Поэтому тем, кто будет заниматься работой с открытыми публичными данными, придется посвятить очень большое количество времени сбору данных и их очистке.
Данные не заменят работу с людьми
Журналистов мне бы хотелось предостеречь от формирования иллюзий, что данные заменят реальную работу журналиста. Данные – это то, что может нас натолкнуть на идею для публикации, показать нам какие-то критические точки, которые требуют внимания журналиста. Но они не заменяют собой саму работу журналиста: общение с людьми и наблюдение за какими-то процессами.
Используйте только те инструменты, которые действительно необходимы
Сейчас инструменты работы с контентом становятся простыми, доступными, бесплатными. Появляется огромное количество возможностей создавать различные мультимедийные эффекты. У журналистов возникает искушение воткнуть в один материал все, что только возможно. Получается такая «новогодняя елка» (на языке веб-дизайнеров): в материале есть немножко текста, огромное количество фотографий (на втором десятке ты начинаешь просто засыпать), по 10 минут видео говорящих голов, интерактивная карта, таймлайн, куча информационных графиков, диаграмм и всего остального.
Возникает ощущение бессмысленности того, что ты видишь, и появляется вопрос: «зачем?».

Один из главных вызовов журналистики данных – это поиск смыслов, понимание, для кого мы это создаем, и о чем мы хотим рассказать. И уже потом – как мы хотим это рассказать. Мы живем в эпоху гигантского разнообразия выбора инструментов для донесения контента. Нужно научиться исключительно хорошо работать с каким-то количеством из них, и те, которые являются наиболее эффективными в конкретной публикации.
Как журналисты работают с данными в Украине?
В Украине за последние годы было несколько успешных проектов, касающихся журналистики данных. Один из них реализуется местным Internews Network – это проект по прозрачности правительства и борьбы с коррупцией.
Несколько лет назад парламент решил, что порядка четверти миллиона человек в стране должны обнародовать свои декларации о доходах, имуществе, счетах в банках – начиная от президента и заканчивая председателем сельского совета, и члены их семей.
Мы решили создать свою систему. Группа местных украинских организаций начала работу по сбору этих данных – разослали несколько десятков тысяч официальных запросов о доступе к декларациям. Они получили очень большое количество сканированных копий документов, заполненных от руки, каждый из которых состоял из 8-10 страниц. Это очень большой объем информации, которую нужно было оцифровать.

Это создало базу данных, в которой можно было анализировать эти данные, сортировать их по разным критериям – по количеству задекларированных денег, земельных участков, автомобилей и так далее. Наличие этой базы данных создало возможность для журналистов всей Украины брать оттуда информацию и проверять, правду ли указали в декларации люди, которые работают за счет налогоплательщиков. Этот массив данных стал источником для более, чем пяти тысяч публикаций, основанных на открытых данных.
Вторая история привела к неожиданным результатами работы с данными.
Украинские железные дороги год назад решили опубликовать сведения о пассажирских перевозках. Этот массив данных включал в себя информацию о пунктах отправления и назначения, номере поезда, дате и времени прибытия и покупки билета. Журналисты из издания texty.org.ua решили проанализировать эту систему – их целью было показать, откуда больше всего ездят украинцы и куда они ездят.
Когда они стали анализировать данные, совершенно неожиданно нашлась другая тема – они увидели, что в период революции в Украине, было зарегистрировано большое количество дополнительных поездов с востока и юга Украины.
Очень большое количество билетов на них покупалось большими партиями – после объявления о продажах, все они выкупались в течение двух часов. Эти поезда прибывали не на большой пассажирский вокзал в Киеве, а на маленькие станции, которые используются для перевалки грузов.
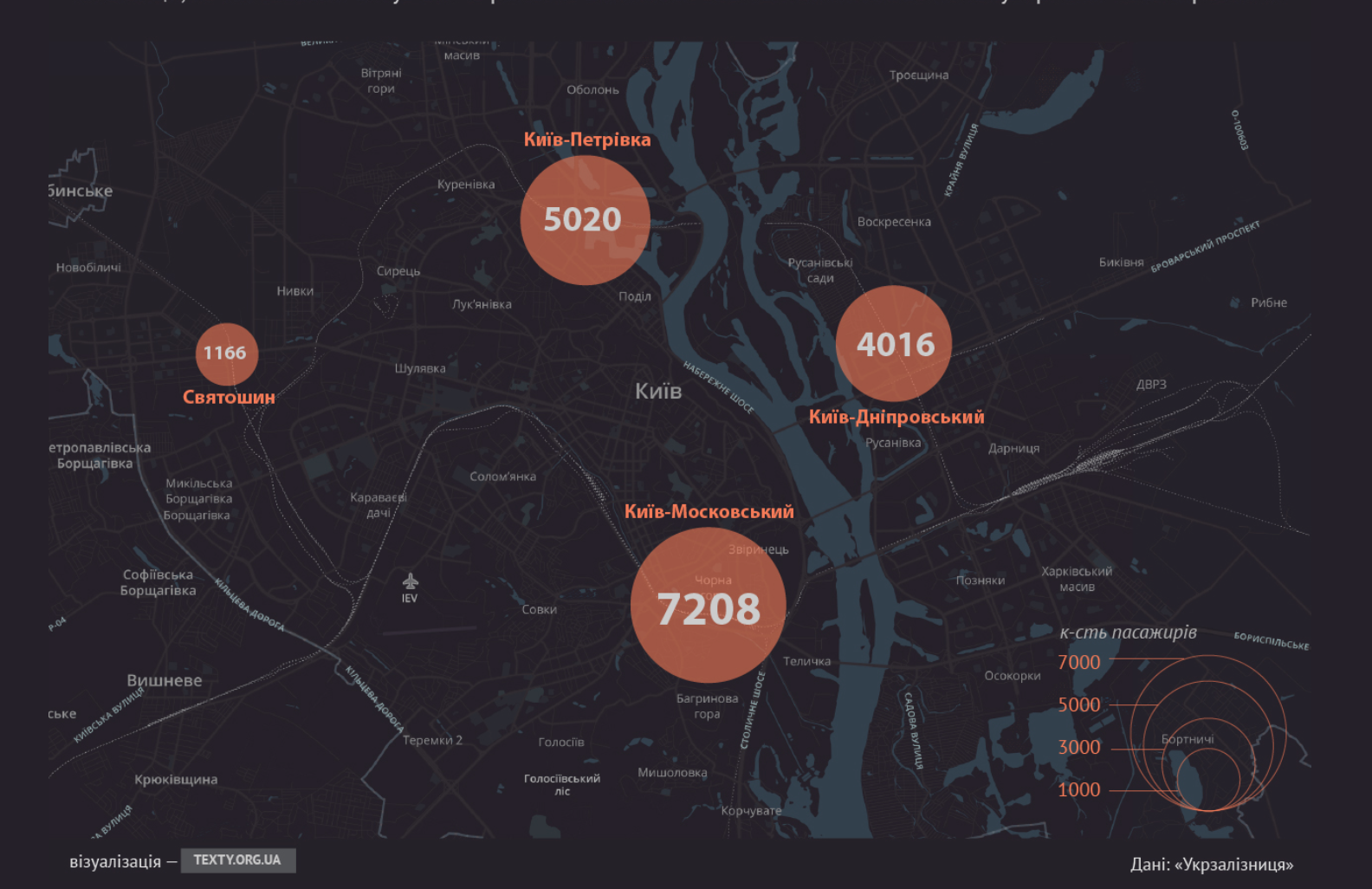
Из этого было логично сделано предположение, что власть организовала подвоз сторонников Януковича в Киев – несколько десятков человек. Этот анализ данных стал большой отправной точкой для журналистского материала. История, основанная на данных без живых людей – это просто статистика. Поэтому журналисты нашли людей, которые ездили в этих поездах и сделали полноценный материал.
ЧИТАЙТЕ ТАКЖЕ
В рубрике «Базы данных» вы можете найти и использовать в своих материалах данные по экологическим темам, разбитые по тематическим секторам и странам Центральной Азии.
Первый центральноазиатский DataLab «Визуализация экологических данных» прошел в Бишкеке с 23 по 25 января. Его организовал проект «Медиа для эффективного освещения вопросов охраны окружающей среды и природных ресурсов в Центральной Азии», который финансируется Европейской комиссией и реализуется Интерньюс.